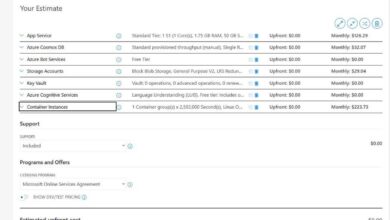
Ever wondered how enterprises move, transform, and orchestrate massive data across clouds and on-premises systems seamlessly? The answer lies in Azure Data Factory—a powerful, cloud-based data integration service that’s revolutionizing how businesses handle data workflows. Let’s dive into what makes it a game-changer.





What Is Azure Data Factory and Why It Matters

Azure Data Factory (ADF) is Microsoft’s cloud ETL (Extract, Transform, Load) service that enables organizations to create data-driven workflows for orchestrating and automating data movement and transformation. Built for the cloud, it allows you to ingest data from diverse sources, transform it at scale, and deliver it to destinations like Azure Synapse Analytics, Azure Data Lake, or even Power BI for visualization.
Core Definition and Purpose
Azure Data Factory is not just another data pipeline tool—it’s a fully managed, serverless data integration service. This means you don’t have to manage infrastructure; ADF handles scaling, availability, and maintenance automatically. Its primary purpose is to streamline the creation of data pipelines that can extract data from heterogeneous sources, apply transformations using compute services like Azure Databricks or HDInsight, and load the results into target systems.
- Supports both code-free visual tools and code-based development (using JSON, SDKs, or REST APIs).
- Enables hybrid data integration—connecting cloud and on-premises data stores.
- Offers built-in connectors to over 100 data sources, including Salesforce, SAP, Oracle, and more.
“Azure Data Factory allows organizations to build scalable data integration solutions without managing infrastructure.” — Microsoft Azure Documentation
How ADF Fits Into Modern Data Architecture
In today’s data-driven world, companies deal with structured, semi-structured, and unstructured data from multiple sources. ADF acts as the backbone of modern data architectures, especially in cloud data platforms like the Azure Data Lakehouse or the Modern Data Warehouse.
It integrates seamlessly with other Azure services such as Azure Blob Storage, Azure SQL Database, and Azure Event Hubs. This interoperability makes ADF a central orchestrator in data pipelines, ensuring that data flows reliably from source to insight.
- Acts as the orchestration layer in a data mesh or data fabric architecture.
- Supports event-driven data processing via triggers and integration with Azure Logic Apps.
- Enables data lineage tracking for governance and compliance.
Key Components of Azure Data Factory
To understand how Azure Data Factory works, you need to grasp its core components. These building blocks form the foundation of every data pipeline you create in ADF.
Linked Services, Datasets, and Pipelines
These three components are the pillars of any ADF implementation.
- Linked Services: Define the connection information to external data sources. For example, a linked service to an Azure SQL Database includes the server name, database name, and authentication details.
- Datasets: Represent data structures within data stores. A dataset points to data in a table, file, or container but doesn’t define the data itself—it’s a reference.
- Pipelines: Logical groupings of activities that perform a specific task. A pipeline might copy data from Blob Storage to SQL Database or trigger a Spark job in Azure Databricks.
Together, these components allow you to define where your data lives, what it looks like, and what you want to do with it.
Activities and Triggers
Activities are the actions performed within a pipeline. Azure Data Factory supports a wide range of activities, including data movement, transformation, and control flow.
- Data Movement Activities: Copy data between sources and sinks. The Copy Activity is one of the most commonly used.
- Transformation Activities: Include HDInsight Hive, Spark, Data Lake Analytics, and custom .NET activities.
- Control Activities: Enable conditional execution, looping, and pipeline chaining (e.g., Execute Pipeline, If Condition, Until Loop).
Triggers, on the other hand, determine when a pipeline runs. ADF supports three types:
- Schedule Triggers: Run pipelines on a recurring schedule (e.g., every hour).
- Event-Based Triggers: Respond to events like file arrival in Blob Storage.
- Manual Triggers: Run pipelines on-demand.
Learn more about triggers in the official Microsoft documentation.
How Azure Data Factory Enables Hybrid Data Integration
One of the standout features of Azure Data Factory is its ability to bridge the gap between cloud and on-premises environments. This hybrid capability is crucial for organizations undergoing digital transformation but still relying on legacy systems.
Understanding the Self-Hosted Integration Runtime
The Self-Hosted Integration Runtime (SHIR) is a key component that enables ADF to connect to on-premises data sources. It’s a lightweight agent installed on a local machine or VM within your corporate network.
- Acts as a bridge between ADF in the cloud and on-premises data stores like SQL Server, Oracle, or file shares.
- Encrypts data in transit using TLS/SSL.
- Can be scaled out by installing multiple instances for high availability and load balancing.
Setting up SHIR involves downloading the installer from the Azure portal, registering it with your ADF instance, and configuring firewall rules to allow outbound HTTPS traffic.
Use Cases for Hybrid Data Movement
Many enterprises use ADF to modernize their data architecture without abandoning existing systems. Common scenarios include:
- Migrating data from on-premises SQL Server to Azure SQL Database or Azure Synapse Analytics.
- Synchronizing customer data from an on-premises CRM system to a cloud data warehouse for real-time analytics.
- Aggregating log files from multiple on-premises servers into Azure Data Lake for centralized monitoring.
This hybrid approach allows for a phased migration strategy, reducing risk and downtime.
Building and Managing Data Pipelines in Azure Data Factory
Creating effective data pipelines is at the heart of what Azure Data Factory does. Whether you’re a developer or a data engineer, ADF provides tools to design, test, and monitor your workflows efficiently.
Using the Visual Interface: Data Factory Studio
Azure Data Factory Studio is a web-based, drag-and-drop interface that simplifies pipeline creation. It’s part of the Azure portal and offers a canvas where you can visually design your data workflows.
- Drag activities from the toolbox and connect them to build pipelines.
- Configure linked services and datasets using intuitive forms.
- Preview data and debug pipelines in real time.
Studio also supports Git integration for version control, enabling team collaboration and CI/CD practices.
Code-Based Development with JSON and SDKs
For advanced users, ADF allows full control via JSON definitions. Every pipeline, activity, and dataset is represented as a JSON object, which can be versioned, templated, and deployed programmatically.
- Use ARM templates to deploy ADF resources across environments (dev, test, prod).
- Leverage Azure PowerShell or Azure CLI to automate pipeline management.
- Integrate with Azure DevOps for CI/CD pipelines using YAML pipelines.
Microsoft provides SDKs for .NET, Python, and Java, allowing developers to interact with ADF programmatically. For example, you can trigger a pipeline run from a custom application using the REST API.
Transformation Capabilities in Azure Data Factory
While ADF excels at data movement, its true power emerges when combined with transformation services. ADF itself is not a compute engine—it orchestrates transformations by delegating them to specialized services.
Mapping Data Flows: No-Code Data Transformation
Mapping Data Flows is ADF’s visual, code-free transformation engine. It runs on Azure Databricks under the hood and allows you to perform complex transformations using a drag-and-drop interface.
- Supports data cleansing, aggregation, joins, and pivoting.
- Provides a data preview feature to validate transformations in real time.
- Generates Spark code automatically, so you don’t need to write it manually.
Data Flows are ideal for ETL scenarios where you want to avoid writing code but still need powerful transformation logic.
Integration with Azure Databricks and HDInsight
For more advanced analytics and machine learning workflows, ADF integrates with Azure Databricks and HDInsight.
- Use the Databricks Notebook Activity to run Python, Scala, or SQL notebooks.
- Trigger Spark jobs on HDInsight clusters for big data processing.
- Pass parameters from ADF to notebooks for dynamic execution.
This integration allows data engineers and data scientists to work in their preferred environments while ADF handles orchestration and scheduling.
Monitoring, Security, and Governance in Azure Data Factory
Enterprise-grade data integration requires robust monitoring, security, and governance. Azure Data Factory delivers on all fronts, ensuring your data pipelines are reliable, secure, and compliant.
Monitoring and Troubleshooting with Azure Monitor
ADF integrates with Azure Monitor to provide comprehensive logging and alerting capabilities.
- View pipeline run history, duration, and status in the Monitoring tab.
- Set up alerts for failed runs or long execution times.
- Stream logs to Log Analytics for advanced querying and dashboarding.
You can also use Application Insights to monitor custom activities or external integrations.
Role-Based Access Control and Data Protection
Security is built into every layer of ADF. It supports Azure Role-Based Access Control (RBAC), allowing you to assign granular permissions to users and groups.
- Define roles like Data Factory Contributor, Reader, or Operator.
- Use Managed Identities for secure authentication to other Azure services.
- Enable private endpoints to restrict data access within a virtual network.
Data in transit is encrypted using HTTPS, and data at rest is encrypted by default using Azure Storage Service Encryption (SSE).
Data Lineage and Compliance
Azure Data Factory supports data lineage tracking through integration with Azure Purview. This allows you to trace the origin and transformation of data across pipelines.
- Visualize how data flows from source to destination.
- Identify dependencies for impact analysis.
- Support GDPR, HIPAA, and other compliance requirements.
Learn more about data governance in ADF at Microsoft Purview integration guide.
Advanced Features and Best Practices for Azure Data Factory
As you grow more proficient with Azure Data Factory, leveraging advanced features and following best practices can significantly improve performance, reliability, and maintainability.
Parameterization and Reusability
One of the most powerful features in ADF is parameterization. You can define parameters at the pipeline, activity, or dataset level to make your pipelines dynamic and reusable.
- Create a single pipeline that processes data for multiple regions by passing a region parameter.
- Use global parameters to define constants like date ranges or connection strings.
- Leverage variables and expressions (using Data Factory’s expression language) for conditional logic.
This reduces duplication and makes pipelines easier to manage at scale.
Error Handling and Retry Logic
Real-world data pipelines must handle failures gracefully. ADF provides built-in retry mechanisms and error handling strategies.
- Set retry counts and intervals for activities that may fail due to transient issues.
- Use the Until or If Condition activities to implement custom retry logic.
- Route failed data to a dead-letter queue or error log for later analysis.
Implementing robust error handling ensures your pipelines are resilient and self-healing.
Performance Optimization Tips
To get the most out of Azure Data Factory, consider these performance best practices:
- Use PolyBase when copying large volumes of data to Azure SQL Data Warehouse for faster loads.
- Enable compression (e.g., GZip) when moving data over the network.
- Partition data sources and sinks to enable parallel copy operations.
- Monitor data throughput and adjust integration runtime settings accordingly.
For detailed guidance, refer to the ADF performance tuning guide.
Real-World Use Cases of Azure Data Factory
Theoretical knowledge is valuable, but seeing how Azure Data Factory is used in real-world scenarios brings its capabilities to life. Let’s explore a few common use cases across industries.
Data Warehousing and Modern Data Platforms
Many organizations use ADF to build and maintain modern data warehouses on Azure. For example, a retail company might use ADF to:
- Extract sales data from on-premises POS systems.
- Transform and enrich it with customer data from CRM.
- Load it into Azure Synapse Analytics for reporting and dashboards.
This enables near real-time business intelligence and decision-making.
IoT and Streaming Data Integration
With the rise of IoT, companies need to process massive streams of sensor data. ADF can ingest data from Azure Event Hubs or IoT Hub, process it in batches, and store it for analysis.
- A manufacturing plant uses ADF to collect machine telemetry every 5 minutes.
- Data is transformed to calculate equipment health scores.
- Results are sent to Power BI for predictive maintenance dashboards.
This helps reduce downtime and optimize maintenance schedules.
Cloud Migration and Data Consolidation
During cloud migration projects, ADF plays a critical role in moving data from legacy systems to the cloud. For instance, a financial institution might use ADF to:
- Migrate customer account data from mainframes to Azure Cosmos DB.
- Consolidate data from multiple regional databases into a central data lake.
- Automate daily reconciliation processes between systems.
This ensures data consistency and accelerates digital transformation.
What is Azure Data Factory used for?
Azure Data Factory is used to create, schedule, and manage data pipelines that move and transform data across cloud and on-premises sources. It’s commonly used for ETL processes, data warehousing, cloud migration, and real-time analytics.
Is Azure Data Factory a ETL tool?
Yes, Azure Data Factory is a cloud-based ETL (Extract, Transform, Load) and data integration tool. While it excels at data movement (ELT), it also supports transformation through integration with services like Azure Databricks, HDInsight, and Mapping Data Flows.
How much does Azure Data Factory cost?
Azure Data Factory pricing is based on usage: pipeline runs, data integration units (DIUs), and data movement. The service offers a free tier with limited monthly activity runs, and pay-as-you-go pricing for production workloads. Costs vary based on volume and complexity.
Can Azure Data Factory replace SSIS?
Yes, Azure Data Factory can replace SQL Server Integration Services (SSIS) in many scenarios, especially for cloud and hybrid workloads. It supports SSIS package migration via the Azure-SSIS Integration Runtime, allowing organizations to lift and shift existing SSIS workloads to the cloud.
How does Azure Data Factory integrate with other Azure services?
Azure Data Factory integrates seamlessly with services like Azure Blob Storage, Azure SQL Database, Azure Synapse Analytics, Azure Databricks, Azure Event Hubs, and Azure Purview. This makes it a central orchestrator in Azure’s data and analytics ecosystem.
In conclusion, Azure Data Factory is more than just a data integration tool—it’s a powerful orchestration engine that empowers organizations to build scalable, secure, and automated data pipelines. Whether you’re migrating to the cloud, building a data warehouse, or processing IoT streams, ADF provides the flexibility and reliability needed to succeed. By mastering its components, leveraging its hybrid capabilities, and following best practices, you can unlock the full potential of your data. The future of data integration is here, and it’s powered by Azure Data Factory.
Recommended for you 👇
Further Reading: